Hedging: A 'Simple' Tactic to Tame Tail Latency in Distributed Systems
Table of Contents
Picture this: your distributed system humming along nicely, serving thousands of requests per second with blazing-fast response times. Then suddenly, a handful of requests start taking ages to complete, and your carefully crafted service level agreements start to crumble. Sound familiar?
This happens due to the notorious tail latency problem—where a small fraction of requests can become the bottleneck that ruins your users’ experience. But fortunately an elegant solution exists that works really well.
Enter hedging—a battle-tested technique used by engineering giants like Google and Grafana to tame these latency spikes. In this post, I’ll explain you how hedging works, and illustrate real-world implementations, and even run some simulations to see its impact firsthand.
You can find the simulation shown below in the GitHub repository hedging-simulation.
The problem: When a few slow responses drag down the whole system
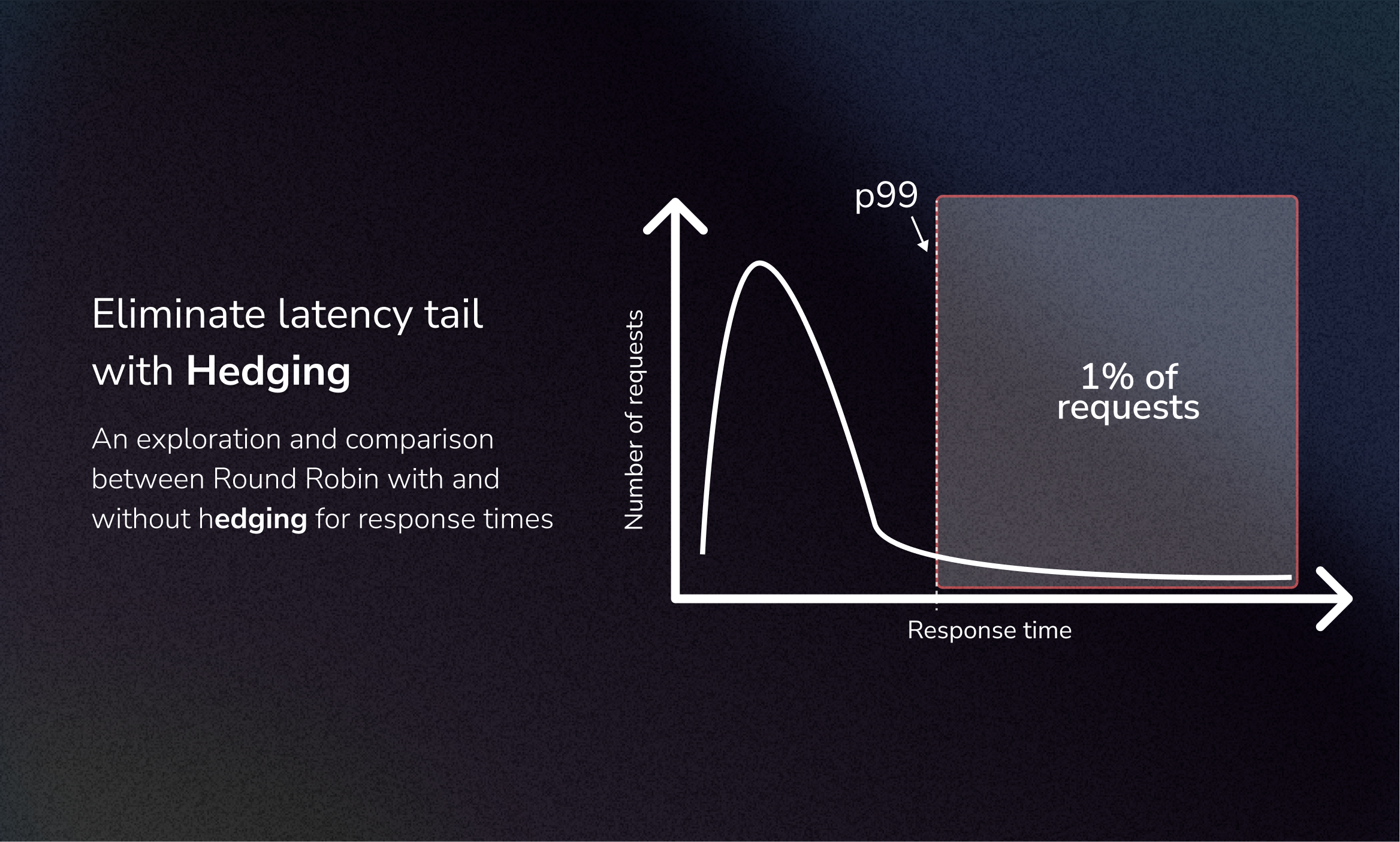
A scenario every distributed systems engineer dreads: your monitoring dashboard shows that 99% of requests complete in under 20 ms, but that stubborn 1% can take 200 ms or more. These outliers don’t represent just statistical anomalies—they represent real users experiencing frustrating delays.
These delays often snowball in microservice architectures, where a single slow response can trigger a cascade of timeouts across your entire system. The result? A degraded user experience, even though “most” of your system performs perfectly.
What exactly is hedging?
Hedging appears in everyday life. Consider booking a ticket to a really popular concert.
On the release date of a popular concert, people often try to log in from different devices at the same time, to make sure that a server serves at least one of their requests. Whichever responds faster, they use that session to book the ticket.
This approach works similarly in the distributed systems world. Hedging functions as an “insurance policy” that kicks in automatically when an issued request/operation starts to slow down.
Hedging functions as an “insurance policy” that kicks in automatically when an issued request starts to slow down.
This approach proves particularly powerful because it is:
- Proactive: Instead of waiting for timeouts, it anticipates potential delays
- Self-healing: Automatically routes around slow servers or network paths
- Low-risk: The overhead stays minimal when your system runs healthy

20 ms of no responseGoogle’s lessons from the field
Google’s engineers have focused on tail latency for years. In their paper The Tail at Scale, they demonstrated that even rare delays can affect a significant fraction of all requests.
For example, in one BigTable benchmark, sending a hedged request after a 10 ms delay reduced the 99.9th percentile latency for retrieving 1,000 keys from 1,800 ms to just 74 ms while incurring only a 2% increase in total requests.
That represents a 96% reduction in tail latency for a negligible increase in load.
Similarly, the MapReduce framework incorporated a similar idea—known as backup tasks—to mitigate stragglers. In practice, jobs that used backup tasks finished in about 891 seconds, whereas disabling these backups led to a total runtime of 1,283 seconds—a 44% increase. In other words, hedging can shave off significant tail delays with minimal overhead.

Benefits of hedging
- Reduced Tail Latency: Hedging minimizes the impact of slow or unresponsive nodes, keeping those latency spikes in check.
- Improved Reliability: By mitigating delays caused by unpredictable slowdowns, your system becomes more resilient to transient issues.
- Enhanced User Experience: More consistent response times build trust and make for a smoother, more predictable experience.
Considerations and best practices
While hedging offers a powerful technique, it doesn’t solve everything. Here are some points to consider:
- Increased Load: Duplicating requests naturally increases the load on your servers. Consider implementing intelligent throttling and monitoring system capacity.
- Idempotent Operations: Ensure that your operations produce the same result when run repeatedly—making identical requests should have the same effect as one. This prevents unintended side effects.
- Timeout Tuning: Selecting the right timeout before issuing a hedged request matters. Too short, and you risk adding unnecessary load; too long, and the benefits of hedging diminish.
- System Complexity: Hedging introduces logic in request handling, so balance the benefits with the added system complexity.
Hedging in practice: A simulation study
Moving from theory to practice, while reading about hedging in the Grafana’s distributed kit, the results of an implementation impressed me—a 45% reduction in tail latency for their distributed tracing system, Tempo. This inspired me to write a simulation to help visualize these benefits.

Setting up the experiment
To keep things realistic yet understandable, the simulation uses these parameters:
📊 The setup:
- 3 backend servers, each typically responding in
10 ms (±5 ms) - Random “hiccups” affecting 3% of requests for only a single server (delays 100-300 ms)
- Load of 200 requests/second
- Total sample size: 20,000 requests
Think of this as a simplified version of a real-world microservice handling user requests.
You can find the complete code for this simulation here.
Baseline: Round robin load balancing
First, you need to know how a traditional round-robin approach performs. It resembles dealing cards at a poker table—each server gets requests in a fixed rotation, regardless of their current performance.

💡 For a deeper look into more sophisticated load balancing, check out Dropbox’s insightful article on their server-load aware approach.
Basic round-robin produced these results:

The numbers tell a story:
- p99 response time:
87 ms(ouch!) - Longest response time:
278 ms(double ouch!)
Fixing the long tail with hedged requests
Now for the interesting part. The simulation includes a straightforward hedging policy:
- Start with a normal request
- If it takes longer than
20 ms, send backup requests to all the other servers - Take whichever response comes first
The policy implements exactly the logic described earlier, or as illustrated in the animation below:
20 ms of no responseBelow you can see the results:

Side-by-side comparison
The following figures compare the results before and after applying hedging, providing a clear view of the benefits:


For the results after applying hedging, you can notice a sharp reduction in tail latencies.
The p99 and p100 metrics appear much closer post-hedging.
Some rough numbers to nerd out:
--------------------------------------------------------------------------------
Metric Original Hedged Absolute Diff % Improvement
--------------------------------------------------------------------------------
mean 12.13 9.71 2.43 20.00%
p95 18.75 17.25 1.49 7.96%
p99 87.88 19.13 68.75 78.23%
p100 278.62 19.94 258.68 92.84%
--------------------------------------------------------------------------------
Conclusion
The numbers don’t lie—hedging provides a powerful tool in your latency-fighting arsenal.
Hedging offers an effective strategy to combat tail latency in distributed systems. By sending duplicate requests and relying on the fastest response, you can drastically reduce the impact of those rare but problematic delays—often with little extra overhead. Whether you’re using it in a tracing system like Grafana Tempo or as part of your own backend architecture, hedging belongs in your latency-reduction toolkit.
Ultimately, building resilient systems means embracing these trade-offs. With a well-tuned hedging policy, you can deliver a more predictable and satisfying user experience even in the face of inevitable system variability.
Should you consider hedging?
Think about hedging if:
- Your system has clear tail latency issues
- You have backend instances available
- Your operations produce identical results when run repeatedly (idempotent operations)
- You can afford a small increase in total request volume
Remember: good enough often beats perfect. You don’t need a complex adaptive algorithm to start seeing benefits—even a straightforward fixed-threshold approach as demonstrated can yield impressive results.
Ready to get started?
If you build distributed systems in Go, here are some battle-tested libraries to help with hedging:
- hedged-http: Drop-in replacement for standard HTTP client with hedging support
- failsafe-go: A comprehensive resilience library with hedging policies
While gRPC offers support for hedged requests, the official implementations include only a Java implementation.
Resources
Want to learn more? A curated list of must-read resources:
- 📚 The Tail at Scale - The seminal paper that started it all
- 🎤 Hedged Requests in Go - A really nice talk about hedged requests from Golang Warsaw
- 🎓 DoltHub’s S3 Variability Reduction - Applying hedging to cloud storage
- 🧪 Toy model of hedging with Python
Remember: in distributed systems, building systems that gracefully handle the unexpected matters more than trying to prevent all failures. Hedging provides one more tool to help you do just that.